Ensar Basri Kahveci
overly distributed
Riding the CP Subsystem
I published this post at Hazelcast blog and put a copy here.
The CP Subsystem of Hazelcast IDMG 3.12 offers a new linearizable implementation of Hazelcast’s concurrency APIs on top of the Raft consensus algorithm. These implementations live alongside AP data structures in the same Hazelcast IMDG cluster (new BFFs, yay!). You can store large data sets on hundreds of Hazelcast members and coordinate your operations using the new safe concurrency primitives that reside in the very same cluster.
This design poses a significant challenge. Hazelcast IMDG is known for its dynamic and elastic clustering capabilities. You can separately configure backups for your data structures, scale out/in your cluster, or replace failed nodes, easy peasy. However, it is quite difficult to propagate dynamicity to a system that works on top of a consensus algorithm. Having membership change capability in the underlying algorithm, i.e., Raft, is one thing, having a full-blown dynamic multi-group consensus system is another thing! We’ve been working hard to make the CP subsystem as easy to use as the rest of the Hazelcast IMDG in terms of clustering and management capabilities.
In this blog post, I’ll walk through a couple of code samples to demonstrate how you can manage the CP subsystem for several scenarios. You can find all of the code samples shown here in our repo.
Please note that all the scenarios that are handled programmatically in this blog post can be also handled via our REST API and management scripts.
Let’s start with the basics.
Config config = new Config();
config.getCPSubsystemConfig().setCPMemberCount(3);
HazelcastInstance hz1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz2 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz3 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz4 = Hazelcast.newHazelcastInstance(config);
for (HazelcastInstance hz : Arrays.asList(hz1, hz2, hz3)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
// We can access to the CP data structures from any Hazelcast member
System.out.println(hz1.getCPSubsystem().getAtomicLong("counter").incrementAndGet());
System.out.println(hz4.getCPSubsystem().getAtomicLong("counter").incrementAndGet());In this code sample, we start a cluster of 4 Hazelcast members and the CP subsystem is configured with 3 CP members. The first 3 members are discovered as CP members and they initialize the CP subsystem in the background. Then, we can start using the new data structures from any Hazelcast member.
Let’s shift up!
Config config = new Config();
config.getCPSubsystemConfig().setCPMemberCount(5);
config.getCPSubsystemConfig().setGroupSize(3);
HazelcastInstance hz1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz2 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz3 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz4 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz5 = Hazelcast.newHazelcastInstance(config);
for (HazelcastInstance hz : Arrays.asList(hz1, hz2, hz3, hz4, hz5)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
CPSubsystemManagementService cpSubsystemManagementService = hz1.getCPSubsystem().getCPSubsystemManagementService();
CPGroup metadataGroup = cpSubsystemManagementService.getCPGroup(CPGroup.METADATA_CP_GROUP_NAME).get();
assert metadataGroup.members().size() == 3;
System.out.println("Metadata CP group has the following CP members: " + metadataGroup.members());
// Let's initiate the Default CP group
hz1.getCPSubsystem().getAtomicLong("counter1").incrementAndGet();
CPGroup defaultGroup = cpSubsystemManagementService.getCPGroup(CPGroup.DEFAULT_GROUP_NAME).get();
assert defaultGroup.members().size() == 3;
System.out.println("Default CP group has the following CP members: " + defaultGroup.members());
// Let's create another CP group
String customCPGroupName = "custom";
hz1.getCPSubsystem().getAtomicLong("counter2@" + customCPGroupName).incrementAndGet();
CPGroup customGroup = cpSubsystemManagementService.getCPGroup(customCPGroupName).get();
assert customGroup.members().size() == 3;
System.out.println(customCPGroupName + " CP group has the following CP members: " + customGroup.members());This time, we configure the CP Subsystem to have 5 CP members, and CP groups will be formed of 3 CP members. Members of a CP group are randomly chosen among all CP members available in the CP subsystem each time a new CP group is created. In our example, we have the Metadata and Default CP groups, and we create another CP group, named: “custom”. These 3 CP groups run independently. Each CP group will have its own Raft leader to commit incoming operations to its majority. By this way, we can distribute our workload among multiple CP groups and Hazelcast members. The following figure presents a simple illustration for this example in which Raft leaders are depicted as bold boxes. The CP groups are formed from a different set of CP members and each CP group elects its Raft leader.
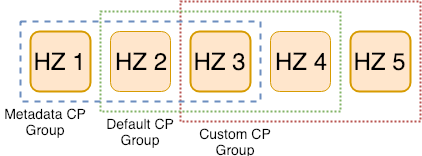
CP Subsystem with 5 CP members and 3 CP groups
No Fun without Failures
OK. Let’s talk about failures. Consider the scenario where we run the CP Subsystem with 5 CP members (the CP group size is also 5) and 2 of them crash. Business as usual, but unfortunately this scenario is risky. If another CP member crashes, the majority of the CP groups will not be satisfied anymore and the CP Subsystem will lose its availability.
There is more than one way to deal with this situation. First, we can reduce the size of the CP Subsystem by removing the failed CP members. When we remove those 2 members, the CP Subsystem will have 3 CP members remaining and the majority will be reduced to 2. Now, we can even handle the crash of a 3rd CP member and continue our operation with 2 CP members. If you are not already impressed, we have a few more tricks left! To recover the CP Subsystem back to 5 CP members, we can promote the regular Hazelcast members to the CP role. For instance, if we promote 3 AP members to the CP role, then all CP groups will have 5 members and the majority value will be restored to 3. Please note that a single Hazelcast member can behave as a CP member and AP member at the same time. Hence, an AP member does not delete its AP data structure data when it is promoted to the CP role.
The following code sample demonstrates this scenario.
Config config = new Config();
config.getCPSubsystemConfig().setCPMemberCount(5);
HazelcastInstance hz1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz2 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz3 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz4 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz5 = Hazelcast.newHazelcastInstance(config);
for (HazelcastInstance hz : Arrays.asList(hz1, hz2, hz3, hz4, hz5)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
IAtomicLong counter = hz1.getCPSubsystem().getAtomicLong("counter");
counter.incrementAndGet();
String hz3CPMemberUid = hz3.getCPSubsystem().getLocalCPMember().getUuid();
String hz4CPMemberUid = hz4.getCPSubsystem().getLocalCPMember().getUuid();
String hz5CPMemberUid = hz5.getCPSubsystem().getLocalCPMember().getUuid();
// 2 CP members crash...
hz3.getLifecycleService().terminate();
hz4.getLifecycleService().terminate();
// Crashed CP members are removed.
CPSubsystemManagementService cpSubsystemManagementService = hz1.getCPSubsystem().getCPSubsystemManagementService();
cpSubsystemManagementService.removeCPMember(hz3CPMemberUid).get();
cpSubsystemManagementService.removeCPMember(hz4CPMemberUid).get();
CPGroup metadataGroup = cpSubsystemManagementService.getCPGroup(CPGroup.METADATA_CP_GROUP_NAME).get();
assert metadataGroup.members().size() == 3;
System.out.println("Metadata CP group has the following CP members: " + metadataGroup.members());
// Whoops! Another CP member crashes...
hz5.getLifecycleService().terminate();
System.out.println("The CP Subsystem is still available with 2 CP members running.");
counter.incrementAndGet();
cpSubsystemManagementService.removeCPMember(hz5CPMemberUid).get();
// Let's start new members and promote them to the CP role
HazelcastInstance hz6 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz7 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz8 = Hazelcast.newHazelcastInstance(config);
hz6.getCPSubsystem().getCPSubsystemManagementService().promoteToCPMember().get();
hz7.getCPSubsystem().getCPSubsystemManagementService().promoteToCPMember().get();
hz8.getCPSubsystem().getCPSubsystemManagementService().promoteToCPMember().get();
// Now all CP groups are recovered back to 5 CP members
metadataGroup = cpSubsystemManagementService.getCPGroup(CPGroup.METADATA_CP_GROUP_NAME).get();
assert metadataGroup.members().size() == 5;
System.out.println("Metadata CP group has the following CP members: " + metadataGroup.members());We can make the CP Subsystem do all of this for us automatically! When a member is removed from the Hazelcast cluster member list, it is not automatically removed from the CP Subsystem. The reason being, failure detection in asynchronous distributed systems is not perfect. What we actually detect is a member has been unresponsive for some duration. Maybe that member is just slowed down under high load, or it is having a long GC pause. There may be a problem with the network, or the member actually crashed. Since Hazelcast IMDG favors availability, it treats all of these cases with the same approach and removes the unresponsive member from the cluster. However, the CP Subsystem follows a more conservative path. It waits for some configurable duration (4 hours by default) before removing the missing CP member automatically. Here, we assume that no temporary problem in our system will take longer than 4 hours. You can configure your duration based on your operational schedule or disable this feature altogether.
In the following code sample, we configure the CP Subsystem to deal with missing CP members 10 seconds after they leave the Hazelcast cluster. Of course, 10 seconds is very short in duration and should not be used in production environments. We use it here to run the code sample in a short time.
Config config = new Config();
CPSubsystemConfig cpSubsystemConfig = config.getCPSubsystemConfig();
cpSubsystemConfig.setCPMemberCount(5);
cpSubsystemConfig.setSessionHeartbeatIntervalSeconds(1);
cpSubsystemConfig.setSessionTimeToLiveSeconds(5);
cpSubsystemConfig.setMissingCPMemberAutoRemovalSeconds(10);
HazelcastInstance hz1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz2 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz3 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz4 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz5 = Hazelcast.newHazelcastInstance(config);
for (HazelcastInstance hz : Arrays.asList(hz1, hz2, hz3, hz4, hz5)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
// We add a new CP member to the cluster.
HazelcastInstance hz6 = Hazelcast.newHazelcastInstance(config);
hz6.getCPSubsystem().getCPSubsystemManagementService().promoteToCPMember().get();
// A CP member crashes...
hz5.getLifecycleService().terminate();
CPSubsystemManagementService cpSubsystemManagementService = hz1.getCPSubsystem().getCPSubsystemManagementService();
// The crashed CP member will be automatically removed and substituted by the new CP member.
while (true) {
CPGroup metadataGroup = cpSubsystemManagementService.getCPGroup(CPGroup.METADATA_CP_GROUP_NAME).get();
if (metadataGroup.members().size() == 5 &&
metadataGroup.members().contains(hz6.getCPSubsystem().getLocalCPMember())) {
System.out.println("The promoted member has been added to the Metadata CP group member list: "
+ metadataGroup.members());
break;
}
Thread.sleep(1000);
}Obliviate to the Rescue!
Since the CP Subsystem works in memory for now, a sudden loss of majority causes total loss of availability for the CP Subsystem. The only solution left is to swing our wand and say “Obliviate!”. We can forcefully terminate the CP Subsystem on the remaining CP members and start the whole thing from scratch with a single API call. In this way, we reset the CP subsystem without shutting down the whole cluster. A geeky version of the Obliviate charm is below.
Config config = new Config();
CPSubsystemConfig cpSubsystemConfig = config.getCPSubsystemConfig();
cpSubsystemConfig.setCPMemberCount(3);
HazelcastInstance hz1 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz2 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz3 = Hazelcast.newHazelcastInstance(config);
for (HazelcastInstance hz : Arrays.asList(hz1, hz2, hz3)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
// 2 CP member crashes and the CP Subsystem loses its availability :(
hz2.getLifecycleService().terminate();
hz3.getLifecycleService().terminate();
// The only option left is to restart the CP Subsystem.
// To do this, we need to make sure that there are 3 members in the Hazelcast cluster
HazelcastInstance hz4 = Hazelcast.newHazelcastInstance(config);
HazelcastInstance hz5 = Hazelcast.newHazelcastInstance(config);
CPSubsystemManagementService cpSubsystemManagementService = hz1.getCPSubsystem().getCPSubsystemManagementService();
cpSubsystemManagementService.restart().get();
for (HazelcastInstance hz : Arrays.asList(hz4, hz5)) {
hz.getCPSubsystem().getCPSubsystemManagementService().awaitUntilDiscoveryCompleted(1, TimeUnit.MINUTES);
System.out.println(hz.getCluster().getLocalMember() + " initialized the CP subsystem with identity: "
+ hz.getCPSubsystem().getLocalCPMember());
}
// The CP subsystem is formed by the new cluster members
Collection cpMembers = cpSubsystemManagementService.getCPMembers().get();
assert cpMembers.size() == 3;
assert cpMembers.contains(hz1.getCPSubsystem().getLocalCPMember());
assert cpMembers.contains(hz4.getCPSubsystem().getLocalCPMember());
assert cpMembers.contains(hz5.getCPSubsystem().getLocalCPMember());
for (HazelcastInstance hz : Arrays.asList(hz1, hz4, hz5)) {
hz.getLifecycleService().terminate();
}Welcome to the Club!
Wow, it has been a long ride… If you are still with me, you have a good potential to be a CP Subsystem rider! You can download the new Hazelcast IMDG 3.12 release and crank your cluster! You can also take a look at our documentation and code samples to learn more about the CP Subsystem.
Stay tuned until next time!