Ensar Basri Kahveci
overly distributed
Testing the CP Subsystem with Jepsen
I published this post at Hazelcast blog and put a copy here.
At Hazelcast we take reliability very seriously. With the new CP Subsystem module, Hazelcast has become the first and only IMDG that offers a linearizable distributed implementation of the Java concurrency primitives backed by the Raft consensus algorithm. In addition to well-grounded designs and proven algorithms, reliability also requires a substantial amount of testing. We have been working hard to ensure the validity of our consistency claims.
In this blog post I’ll try to demystify the linearizability semantics of the CP Subsystem and explore our Jepsen test suite. This blog post is the fourth installment of my CP Subsystem blog post series.
Our work with Jepsen has now become a part of the official Jepsen repo so it’s easily accessible to everyone interested. To avoid any confusion, let me point out that we didn’t conduct any joint work with Kyle Kingsbury. His involvement with our work started after we sent our pull request.
Jepsen: The Kryptonite of Distributed Databases
I discovered Jepsen shortly after joining Hazelcast in 2015. Hazelcast engineers were already big fans of the Jepsen reports back then and they welcomed me to the club. Over the years, we witnessed how Jepsen became the industry-standard tool for testing consistency claims of distributed databases and made significant contributions to the industry. We are grateful that Kyle Kingsbury put Hazelcast on his radar in 2017 as his analysis and recommendations were very helpful. In Hazelcast IMDG 3.10, we introduced flake ID generators and CRDT counters, enhanced our split-brain handling mechanisms, and revised our consistency claims in our documentation. We finally introduced the CP Subsystem module in Hazelcast IMDG 3.12.
Running a Jepsen test on a distributed database is like sneaking up on Superman with kryptonite while he is trying to overcome his biggest challenge. Jepsen subjects the database to various system failures while running a test case and checks whether the database is able to maintain its consistency promises. It can create chaos in many ways: make a single node or multiple nodes crash or hiccup, partition the network, or even make clocks go crazy.
The Linearizability Semantics of CP Subsystem
We wrote our Jepsen tests to verify that the new implementations of our concurrency APIs work as expected with respect to the linearizability semantics of the CP Subsystem. We should first clarify our linearizability semantics before talking about the tests.
If you aren’t yet familiar with CP Subsystem, you can read our CP Subsystem primer. In short, we have a notion of CP groups. A CP group is a cluster on its own with respect to the CP services it provides. You can run multiple CP groups and distribute your CP concurrency primitives to them. Each CP group executes the Raft consensus algorithm independently. The Raft consensus algorithm provides a single serial commit order for submitted operations and guarantees that each committed operation runs on the latest state of the CP group.
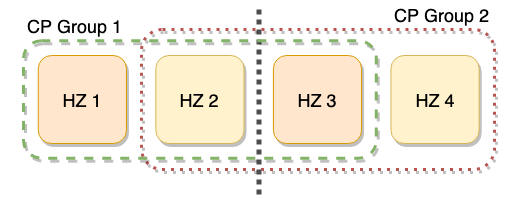
This design implies that each CP group will have its own availability. Consider a scenario where the CP group size is set to 3 and there are 4 CP members. We run 2 CP groups in this setup and they are initialized as shown below. Suppose that we create an IAtomicLong instance in each CP group. If a network partition splits our cluster as in the figure below, our CP groups will have their majority on different sides of the partition. It means that we will preserve the availability of the first IAtomicLong instance, but lose it for the second IAtomicLong instance on the left side, and vice-versa for the right side.
Having the Raft consensus algorithm under the hood is not sufficient itself to guarantee linearizability for the operations running on all concurrency APIs of the CP Subsystem. We need to make sure that the internal state machines are implemented correctly. This requires all operations to be deterministic, but there is always some source of non-determinism in real-world APIs. For instance, FencedLock offers locking methods, i.e., the variances of tryLock(timeout), that take a timeout parameter to specify how long a call should be blocked if the lock is already held. We must extract non-determinism from the FencedLock state machine while handling tryLock(timeout) calls. It means that replicas of the FencedLock state machine should not apply timeouts independently. What we do is, we make the Raft leader of the underlying CP group responsible for timeout decisions. The Raft leader keeps track of committed tryLock(timeout) calls to decide which calls should time-out and commits those timeouts to the CP group. Through this method, we handle tryLock() timeouts deterministically. The very same logic applies to tracking liveness of CP sessions.
We also need to think about retries of in-flight operations. Consider a scenario where the Raft leader node of a CP group receives an operation from a client, but crashes before responding to the client. In this case, the client cannot easily determine if its operation was committed or not. If the client retries its call naively, it can cause the operation to be committed and executed twice, if the leader managed to commit the operation before crashing. We have an internal interface that is implemented by the operations committed in CP groups. This interface denotes if an operation can be retried safely if its current status is indeterminate. If the operation is idempotent, a duplicate commit does not create a problem because the result will be the same as if the operation is committed only once. For instance, read-only operations are always retried. However, all write operations are not idempotent by nature, so we need to implement a generic de-duplication mechanism to safely handle retries of all kinds of write operations and maintain the exactly-once semantics. Diego Ongaro does not cover de-duplication in the core Raft consensus algorithm, but discusses it as an extension in his Ph.D. thesis (Section 6.3: Implementing linearizable semantics). Since a generic de-duplication mechanism brings a significant amount of complexity into the implementation, we preferred to skip it in our initial release. Instead, we handled internal retries of the CP Subsystem API calls in different ways. We managed to offer the exactly-once execution semantics on FencedLock, ISemaphore, and ICountDownLatch by taking advantage of the restrictions on these APIs and marking their internal operations as retryable. We run a simple and effective de-duplication mechanism for them behind the scenes. On the other hand, we don’t offer the exactly-once semantics for IAtomicReference and IAtomicLong. Instead, we allow developers to decide between the at-most-once and at-least-once execution semantics for these APIs via configuration. The internal operations of IAtomicReference and IAtomicLong primitives return their retryable status by checking this configuration. We are planning to extend our de-duplication mechanism to cover the whole CP Subsystem API suite.
The linearizability semantics of the CP Subsystem are summarized as follows:
- Each CP group runs the Raft consensus algorithm independently. The Raft consensus algorithm provides a single serial commit order for submitted operations and guarantees that each committed operation runs on the latest state of the CP group.
- All kinds of non-determinism and randomness are extracted from the core Raft mechanics. All API methods provided by the CP concurrency primitives, including the ones that work with timeouts, internally run on CP group members deterministically.
FencedLock,ISemaphore, andICountDownLatchAPIs offer linearizability with exactly-once execution semantics, including the case of Raft leader failures. However, in order to get linearizability forIAtomicReferenceandIAtomicLongprimitives, you need to disable automatic retries in case of Raft leader failures.
CP Subsystem Jepsen Test Setup
In order to minimize the bias for testing our own system, we built our test setup on top of the infrastructure Kyle Kingsbury introduced in his Hazelcast analysis. We run the CP Subsystem with 5 CP members and use a single CP group (the Default CP group). The timeouts are tuned to react to failures quickly. Raft leader heartbeat timeout is set to 5 seconds, which implies that the follower nodes of the Default CP group try to elect a new leader 5 seconds after they don’t receive any heartbeat from the current leader. Hazelcast operation call timeout is also set to 5 seconds. Last, CPSubsystemConfig.isFailOnIndeterminateOperationState() is set to true to disable automatic retries for IAtomicLong and IAtomicReference.
Each test performs a sequence of operations on the new concurrency primitives via Hazelcast clients. While running those tests, we introduce network partitions lasting 20 seconds via the partition-majorities-ring nemesis, followed by 20 seconds of full connectivity for recovery. Jepsen logs every performed operation with its result. At the end, the linearizability checker validates that the results are consistent with the operation history with respect to the invariants offered by the tested concurrency primitive.
For instance, we use the IAtomicLong.compareAndSet() method in our IAtomicLong tests. These calls can have 3 different outcomes. A compareAndSet() call succeeds if the current value of the IAtomicLong instance is equal to the expected value when the call is committed on the CP group. Since we are making compareAndSet() calls from multiple clients concurrently, a compareAndSet() call can return with failure if the value of the IAtomicLong instance changes in the meantime. It can also have an indeterminate result, for instance if the operation times out or the Raft leader becomes unreachable due to a network partition problem. Since an indeterminate compareAndSet() call could be applied or not applied, it causes a fork in the operation history during the validation phase.
We run our Jepsen test suite in our continuous integration pipeline using Docker containers. You can also run our tests on your computer by following the instructions given in the Jepsen repository.
CP Subsystem Jepsen Test Cases
We have 8 test cases for the CP Subsystem:
- Non-reentrancy of
FencedLock: In this test case, and also in the otherFencedLocktests, clients maketryLock()andunlock()calls. Then, we check ifFencedLockbehaves as a non-reentrant mutex, i.e., it can be held by a single endpoint at a time and only the lock holder endpoint can release it. Moreover, the lock cannot be acquired by the same endpoint reentrantly. - Reentrancy of
FencedLock: We test ifFencedLockbehaves as a reentrant mutex. The lock instance can be held by a single endpoint at a time and only the lock holder endpoint can release it. Moreover, the current lock holder can reentrantly acquire the lock one more time. Reentrant lock acquire limit is 2 for this test. - Monotonicity of fencing tokens for non-reentrant
FencedLock:FencedLockorders lock holders by a monotonic fencing token, which is incremented each time the lock switches from the free state to the held state. In this test case, we validate monotonicity of fencing tokens assigned to subsequent lock holders. Moreover, the lock cannot be acquired by the same endpoint reentrantly. - Monotonicity of fencing tokens for reentrant
FencedLock:FencedLockorders lock holders by a monotonic fencing token, which is incremented each time the lock switches from the free state to the held state. However, if the current lock holder acquires the lock reentrantly, it will get the same fencing token. Reentrant lock acquire limit is 2 for this test. ISemaphorepermits: In this test, we initialize anISemaphoreinstance with 2 permits. Each client tries to acquire and release a permit in a loop and we validate that permits are held by at most 2 clients at any time.- Unique ID generation with
IAtomicLong: In this test, each client generates a uniquelongid by using anIAtomicLonginstance and we validate uniqueness of generated ids. Compare-and-swapregister withIAtomicLong: In this test, clients randomly performread,writeandcompare-and-setoperations. We validate the history with thecas-registermodel of Jepsen.Compare-and-swapregister withIAtomicReference: In this test, clients randomly performread,writeandcompare-and-setoperations. We validate the history with thecas-registermodel of Jepsen.
We fixed all the bugs revealed by these test cases and currently do not have any known bugs.
The current test suite uses a static CP member set. Even though we may have multiple Raft leader elections because of network partitions, we do not crash CP members and replace them with new ones during test runs. We are planning to extend our test suite with crash failures and dynamic CP membership changes.
Revealing Issues and Evolving a Design
The roots of CP Subsystem’s testing procedure go back to the early days of its development. We had a passing Jepsen test three weeks after the first commit of our Raft consensus algorithm implementation. Once we had the leader election and log replication components of Raft, we implemented our IAtomicLong primitive on top of it and then tested that implementation with Jepsen. As we made progress, a feedback loop came to light by itself between our development and testing efforts. I like to think of our experience as a different form of test-driven development. Our Jepsen tests worked like unit tests and helped not only reveal bugs, but also improve the internal design and external semantics of our new concurrency primitives. For the FencedLock and ISemaphore tests, most of the test failures were related to the de-duplication mechanism which handles internal retries. In addition, we discovered several problems in the reentrancy logic of FencedLock. Each test failure revealed another corner case missed by our design. We passed through countless iterations until we arrived at the current design and implementation of FencedLock and ISemaphore.
Here is a list of some issues and commits to show the evolution of FencedLock and ISemaphore:
- [1], [2], [3], [4], [5]
FencedLockis reentrant by default. Until we ended up with the current design, we moved back and forth between non-local and local implementation of reentrancy. Handling reentrancy locally means that aFencedLockproxy holds its reentrant lock acquires as local state. Its alternative solution, which is the current solution in place, is to keep no local state for reentrancy and hit the CP group for everylock()/unlock()call. Handling reentrancy locally sounds like a reasonable approach, and we went for it a couple of times. Once an endpoint acquires the lock, other endpoints are usually not interested in how many times the lock is acquired reentrantly. However, the devil is in the details. When we keep reentrancy state locally insideFencedLockproxies, it effectively becomes another replica of theFencedLockstate and several problems appear if failures occur while communicating with the CP group. We repeated a “discover a problem -> spend days thinking about possible solutions -> try these solutions -> discover another problem” loop for weeks and finally decided to abandon the local reentrancy approach. If you want to learn more about FencedLock, you can check our “Distributed Locks are Dead; Long Live Distributed Locks!” blogpost. - [6] We also enabled a configurable reentrancy behavior for
FencedLock. You can use it as a binary mutex, set a custom reentrancy limit, or keep the default behavior where there is no limit for non-reentrancy. This configuration option has been very useful for testing FencedLock properly. - [7], [8], [9], [10] Several problems related to making
FencedLockandISemaphoreAPIs idempotent were found and fixed. - [11] Suppose you make a
tryLock(timeout)call while the lock is already being held. If the lock is not released before the timeout occurs, yourtryLock()call returnsfalse, meaning that you could not acquire the lock. However, if the lock is released just after that, the lock could be assigned to you faultily, because of an internal retry previously done for yourtryLock()call. - [12], [13] We built an internal generic solution for automatic retries of CP API calls. If an API method can be implemented in a way that is safe to retry, i.e, idempotent, it is automatically retried on certain failures. Otherwise,
CPSubsystemConfig.failOnIndeterminateOperationStateis respected. - [14] Several problems were found and fixed for taking snapshots of the blocking concurrency primitives’ state machines.
- [15], [16], [17] Several problems related to handling of operation timeouts were found and fixed.
The Many Faces of Distributed Systems Resiliency Testing
One interesting fact about our testing experience is that our Jepsen tests did not reveal any correctness bug in the leader election and log replication components of our Raft implementation. All bugs and problems discovered turned out to be related to the state machine implementations of our concurrency primitives.
This is not to say that our Raft algorithm implementation has been bulletproof from day one. Our Raft algorithm implementation lives in the Hazelcast codebase, but it is highly isolated from the rest of the Hazelcast code. It depends on Hazelcast mostly for the logging and testing utilities. We developed and tested our core Raft implementation by running Raft nodes on multiple threads of a single process and making them communicate via message passing. We also managed to build a comprehensive unit and micro-integration test suite for this implementation.
Micro-integration test is a term we coined in Hazelcast a couple of years ago. In fact, most of the tests in the whole Hazelcast codebase can be classified as micro-integration tests. Its scope is wider than a unit test, but it usually does not use a real network or a file system. We mimic message losses, delays, crashes in our micro-integration tests. When we suspect a weird behavior related to the Raft logic, we first write a micro-integration test for it. Our micro-integration test suite revealed several problems related to log replication, leader election, snapshotting, membership changes, and performance optimizations on Raft. As of now, we have 120 unit and micro-integration tests for our Raft algorithm implementation. In addition to these tests, we also have a bundle of 562 micro-integration tests that covers the whole CP Subsystem module.
We also have our in-house “Chaos Monkey” tool. We have been using it to test the resiliency of Hazelcast IMDG for a long time. It puts an Hazelcast IMDG cluster under varying degrees of workloads and troubles the cluster in parallel to check if the cluster members fall into latency spikes, long GC cycles, deadlocks, or OOMEs. We also used our chaos testing tool to write 35 different chaos tests for the CP Subsystem. In these tests, most of which are running for hours, we drop network connections between cluster members, create and resolve network partitions, randomly crash and restart CP members, and invoke the dynamic clustering APIs of the CP Subsystem. Then, we check if the CP Subsystem encounters a deadlock, an internal exception leaks to the user, internal state of the concurrency primitives gets corrupted, etc. These chaos tests turned out to be another pillar of our testing process. They revealed a few critical issues in the leader election, snapshotting and membership change components of the Raft algorithm implementation:
- [18] If a snapshot is already installed by a follower, it must reply to the leader on a duplicate
InstallSnapshotRPCso that the leader can advance itsmatch index. - [19] Multiple membership changes can be committed before a slow follower appends and commits them. When a slow follower appends these changes, it needs to commit each membership change one by one.
- [20] A Raft leader can take a snapshot using the committed member list even when there is an ongoing membership change.
- [21] If a Raft leader is elected very quickly, even before some of the CP group members initialize their Raft state, those late members can get stuck in the pre-voting phase because of a racy initial term.
Last, our chaos tests revealed many problems also in the dynamic clustering capabilities of the CP Subsystem.
Wrapping up
Jepsen has became one of the pillars of our test suite to ensure the reliability of the CP Subsystem. In this blog post, I was planning to give more details about how we coped with several challenges while trying to test FencedLock with Jepsen and how we improved the design of FencedLock throughout our testing process. However, this post has become longer than I anticipated. So I will do it in another blog post…
Happy hacking until then.